Multi-Modal Architecture Design
Overview
Multi-modal AI processes and understands multiple data types - text, images, audio, and video - enabling richer applications that mirror human perception. Modern enterprises have data spanning documents, presentations, images, recordings, and more. Multi-modal architectures unlock insights from all these formats.
Amazon Bedrock provides comprehensive multi-modal capabilities through vision-language models, multi-modal embedding models, and integration with AWS speech services like Transcribe and Polly. This topic covers architecture patterns for building multi-modal GenAI applications.
Key Principle
Multi-modal AI enables cross-modal retrieval - searching for images using text, finding documents based on video content, or building assistants that can "see" charts and "hear" recordings. Amazon Nova Multimodal Embeddings unifies all modalities in a single vector space.
Know which models support which modalities. Claude 3 and Nova support image input; Titan Multimodal Embeddings supports text and images; Nova Multimodal Embeddings supports text, images, audio, video, and documents in a unified space.
Architecture Diagram
The following diagram illustrates a multi-modal architecture with different input types:
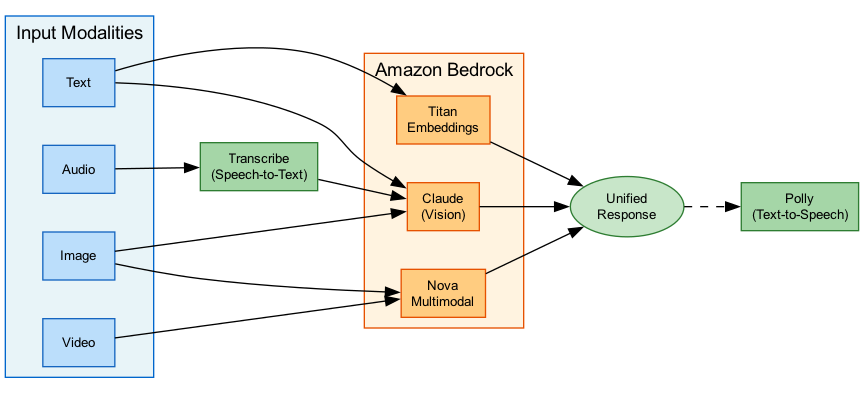
Key Concepts
Text, Image, and Audio Processing
Multi-Modal Input Types
Supported Modalities in Bedrock:
| Modality | Input Models | Embedding Models | |----------|--------------|------------------| | Text | All LLMs | Titan Text, Cohere, Nova | | Images | Claude 3, Nova, Llama Vision | Titan Multimodal, Nova Multimodal | | Audio | Nova Multimodal (embeddings) | Nova Multimodal | | Video | Nova Pro/Lite (understanding) | Nova Multimodal | | Documents | Claude 3, Nova, Bedrock Data Automation | Nova Multimodal |
Vision-Language Models (VLMs):
- Process images alongside text prompts
- Document understanding (tables, charts, images)
- Visual Q&A and analysis
- Available: Claude 3 family, Amazon Nova, Llama 3.2 Vision
Image Processing
Image Input Capabilities:
Claude 3 Vision:
- Accepts images up to 20MB
- Supports JPEG, PNG, GIF, WebP
- Multiple images per request
- Best for: Document analysis, visual Q&A
Amazon Nova Vision:
- Native multi-modal understanding
- 300K context with images
- Best for: Complex visual reasoning
Use Cases:
- Extract text from screenshots
- Analyze charts and graphs
- Describe product images
- Compare visual documents
- OCR-like extraction
import boto3
import base64
bedrock = boto3.client('bedrock-runtime')
# Read and encode image
with open('document.png', 'rb') as f:
image_data = base64.standard_b64encode(f.read()).decode('utf-8')
response = bedrock.converse(
modelId='anthropic.claude-3-sonnet-20240229-v1:0',
messages=[
{
'role': 'user',
'content': [
{
'image': {
'format': 'png',
'source': {'bytes': base64.b64decode(image_data)}
}
},
{
'text': 'Extract all text from this document and summarize the key points.'
}
]
}
]
)
print(response['output']['message']['content'][0]['text'])Multi-Modal Embedding Strategies
Multi-Modal Embeddings
Embedding Models for Multi-Modal:
Amazon Titan Multimodal Embeddings G1:
- Text and image embeddings
- 1024-dimension vectors
- Two-tower architecture (text + image encoders)
- Up to 128 tokens for text
- Best for: Image search, product matching
Amazon Nova Multimodal Embeddings:
- Unified model for ALL modalities
- Text, images, audio, video, documents
- Dimension options: 256, 384, 1024, 3072
- 8K token text, 30-second audio/video
- Industry-leading cross-modal accuracy
- Best for: Enterprise multimodal RAG
Unified Vector Space
Cross-Modal Retrieval:
Nova Multimodal Embeddings creates a unified semantic space where:
- Text queries find relevant images
- Image queries find similar documents
- Audio clips retrieve related videos
- All modalities are comparable
Use Cases:
- Search product catalog with text OR image
- Find meeting recordings by topic
- Retrieve documents that match a chart
- Build visual similarity search
Architecture:
Input (any modality) → Nova Multimodal Embeddings
↓
Vector (256-3072 dim)
↓
OpenSearch / pgvector
↓
Retrieved content (any modality)
Embedding Model Comparison
| Model | Modalities | Dimensions | Max Input | Best For |
|---|---|---|---|---|
| Titan Text Embeddings V2 | Text only | 256, 512, 1024 | 8K tokens | Text-only RAG |
| Titan Multimodal G1 | Text, Images | 1024 | 128 tokens, images | Image search |
| Nova Multimodal | Text, Image, Audio, Video, Docs | 256, 384, 1024, 3072 | 8K tokens, 30s media | Enterprise multimodal |
| Cohere Embed | Text only | 1024 | 512 tokens | Multilingual text |
Cross-Modal Retrieval
Cross-Modal RAG
Multimodal RAG Architecture:
Knowledge Base Configuration:
Data Sources:
- S3 (documents, images)
- SharePoint (presentations)
- Confluence (mixed content)
↓
Bedrock Data Automation (preprocessing)
↓
Nova Multimodal Embeddings (vectorization)
↓
OpenSearch Serverless (vector store)
↓
Multimodal RAG queries
Bedrock Knowledge Bases Multimodal:
- GA in November 2025
- Unified workflow for text, images, audio, video
- Automatic chunking and embedding
- Cross-modal search out of the box
Retrieval Strategies
Multi-Modal Retrieval Patterns:
1. Text-to-Image Search:
"red sports car on mountain road"
↓
Nova Embeddings
↓
Vector similarity
↓
Matching images
2. Image-to-Document Search:
[Chart image] → "Find documents with similar data"
↓
Combined embedding
↓
Related reports, presentations
3. Audio-to-Text Search:
[Audio clip] → Find related meeting notes
↓
Audio embedding
↓
Text documents discussing same topic
4. Hybrid Query:
[Image] + "Explain this architecture"
↓
Multi-modal context retrieval
↓
LLM generates explanation
Vision-Language Models
VLM Capabilities
Vision-Language Model Use Cases:
Document Understanding:
- Extract tables from PDFs
- Interpret charts and graphs
- Read handwritten notes
- Process forms and invoices
Visual Analysis:
- Describe image content
- Answer questions about images
- Compare multiple images
- Detect objects and text
Available VLMs on Bedrock: | Model | Strengths | |-------|-----------| | Claude 3.5 Sonnet | Complex reasoning, long documents | | Claude 3 Haiku | Fast, cost-effective | | Amazon Nova Pro | 300K context, AWS native | | Llama 3.2 Vision | Open weights, customizable |
VLM Comparison
| Model | Max Images | Context | Strengths |
|---|---|---|---|
| Claude 3.5 Sonnet | 20 | 200K tokens | Best reasoning, document analysis |
| Claude 3 Haiku | 20 | 200K tokens | Fast, cost-effective |
| Amazon Nova Pro | Multiple | 300K tokens | Video understanding, AWS native |
| Llama 3.2 90B Vision | Multiple | 128K tokens | Open weights, customizable |
Audio Transcription and Synthesis
Speech Pipeline
Voice-Enabled GenAI Architecture:
User Speech → Amazon Transcribe (STT)
↓
Bedrock (Nova/Claude)
↓
Amazon Polly (TTS)
↓
Audio Response
Amazon Transcribe:
- Real-time streaming transcription
- 100+ languages
- Speaker diarization
- Channel identification
- Custom vocabulary
Amazon Polly:
- 60+ voices, 30+ languages
- Neural and generative voices
- SSML support
- Real-time streaming
Voice Agent Architecture
Building Voice Agents:
Components:
- ASR (Transcribe) - Speech to text
- NLU (Bedrock) - Intent understanding
- Dialog (Bedrock Agents) - Conversation management
- TTS (Polly) - Text to speech
Streaming Pipeline:
Microphone → WebSocket → Transcribe Streaming
↓
Lambda → Bedrock
↓
Polly → WebSocket
↓
Speaker
New: Amazon Nova Sonic:
- Real-time conversational AI
- Sub-300ms latency
- Native speech understanding
- Expressive voice synthesis
import boto3
transcribe = boto3.client('transcribe')
bedrock = boto3.client('bedrock-runtime')
polly = boto3.client('polly')
def process_voice_query(audio_file_uri):
# Step 1: Transcribe audio to text
transcribe.start_transcription_job(
TranscriptionJobName='voice-query',
Media={'MediaFileUri': audio_file_uri},
MediaFormat='wav',
LanguageCode='en-US'
)
# ... wait for completion and get transcript ...
transcript = "User's spoken question here"
# Step 2: Process with Bedrock
response = bedrock.converse(
modelId='anthropic.claude-3-sonnet-20240229-v1:0',
messages=[{'role': 'user', 'content': [{'text': transcript}]}]
)
answer = response['output']['message']['content'][0]['text']
# Step 3: Convert response to speech
polly_response = polly.synthesize_speech(
Text=answer,
OutputFormat='mp3',
VoiceId='Joanna',
Engine='neural'
)
return polly_response['AudioStream'].read()How It Works
Bedrock Data Automation Pipeline
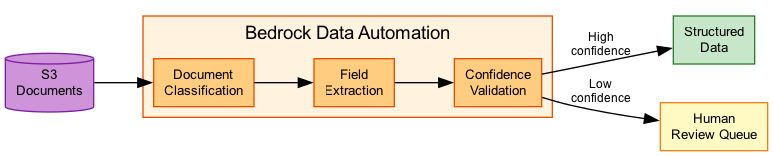
Cross-Modal Retrieval Flow
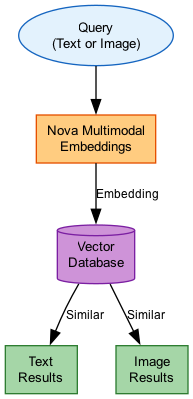
Use Cases
Use Case 1: Multimodal Enterprise Search
Scenario: Search across documents, images, and meeting recordings with natural language.
Architecture:
Data Sources (S3):
- PDF documents
- PowerPoint slides
- Images and diagrams
- Meeting recordings
↓
Bedrock Data Automation
↓
Nova Multimodal Embeddings
↓
OpenSearch Serverless
↓
Search API (API Gateway + Lambda)
User Experience:
- "Find presentations about Q3 revenue"
- "Show me architecture diagrams like this one" [uploads image]
- "Find meetings where we discussed the merger"
Use Case 2: Visual Document Processing
Scenario: Extract data from invoices, forms, and mixed-content documents.
Architecture:
S3 (documents) → Bedrock Data Automation
↓
Claude 3.5 Vision
↓
Structured JSON
↓
DynamoDB (storage)
Processing Capabilities:
- Extract tables from PDFs
- Read handwritten forms
- Interpret charts and graphs
- Cross-reference with text content
Use Case 3: Voice-Enabled Customer Service
Scenario: AI-powered phone support with speech recognition and synthesis.
Architecture:
Phone Call → Amazon Connect
↓
Transcribe (streaming)
↓
Bedrock Agent (Claude)
↓
Knowledge Base (RAG)
↓
Polly (streaming)
↓
Audio Response
Features:
- Real-time speech recognition
- Context-aware responses
- Natural voice synthesis
- Multi-turn conversation support
Best Practices
Multi-Modal Best Practices
- Use unified embeddings - Nova Multimodal Embeddings for cross-modal search
- Preprocess with Data Automation - Handles chunking and extraction automatically
- Choose appropriate VLMs - Claude 3.5 for documents, Nova for video understanding
- Optimize image size - Compress images to reduce token costs
- Stream audio pipelines - Use streaming APIs for low-latency voice
- Consider dimension tradeoffs - Lower dimensions for speed, higher for accuracy
- Test cross-modal accuracy - Validate retrieval quality across modalities
Common Exam Scenarios
Exam Scenarios and Solutions
| Scenario | Solution | Why |
|---|---|---|
| Search images with text queries | Nova Multimodal Embeddings + vector DB | Unified embedding space for cross-modal search |
| Extract tables from PDF documents | Claude 3.5 Sonnet with vision | Best document understanding capability |
| Build voice-enabled chatbot | Transcribe → Bedrock → Polly pipeline | Standard speech-to-speech architecture |
| Process video for insights | Amazon Nova Pro with video input | Native video understanding support |
| Enterprise multimodal RAG | Bedrock Knowledge Bases with multimodal retrieval | Managed solution for all modalities |
Common Pitfalls
Pitfall 1: Using Text-Only Embeddings for Images
Mistake: Trying to search images using text-only embedding models.
Why it's wrong: Text embeddings cannot capture visual semantics; results will be poor or random.
Correct Approach:
- Use Titan Multimodal or Nova Multimodal Embeddings
- Embed both text and images in same vector space
- Use cross-modal retrieval for search
Pitfall 2: Ignoring Image Token Costs
Mistake: Sending high-resolution images without optimization.
Why it's wrong: Large images consume many tokens, increasing costs significantly.
Correct Approach:
- Resize images to reasonable dimensions
- Compress when quality allows
- Use appropriate image format (WebP for web)
- Monitor token usage for image requests
Pitfall 3: Synchronous Voice Processing
Mistake: Using batch transcription for real-time voice applications.
Why it's wrong: Introduces unacceptable latency for conversational applications.
Correct Approach:
- Use Transcribe streaming for real-time STT
- Stream Bedrock responses token-by-token
- Use Polly streaming for immediate playback
- Consider Nova Sonic for sub-300ms latency
Test Your Knowledge
A company wants to build a search system that can find relevant images using text queries and find related documents using image queries. Which embedding model should they use?
What is the correct architecture for a real-time voice-enabled chatbot?
Which model should be used for extracting tables and understanding charts from complex PDF documents?
Related Services
Quick Reference
Multimodal Model Capabilities
Text Image Audio Video Docs
Claude 3.5 Sonnet ✓ ✓ (in) - - ✓
Claude 3 Haiku ✓ ✓ (in) - - ✓
Amazon Nova Pro ✓ ✓ (in) - ✓ (in) ✓
Amazon Nova Lite ✓ ✓ (in) - ✓ (in) ✓
Llama 3.2 Vision ✓ ✓ (in) - - -
Titan Image Generator ✓ (prompt) - ✓ (out) - -
Embedding Models:
Titan Text V2 ✓ - - - -
Titan Multimodal G1 ✓ ✓ - - -
Nova Multimodal ✓ ✓ ✓ ✓ ✓
(in) = input supported, (out) = output generatedVoice Pipeline Components
Speech Services Comparison
| Service | Direction | Streaming | Use Case |
|---|---|---|---|
| Amazon Transcribe | Speech → Text | Yes | Voice input processing |
| Amazon Polly | Text → Speech | Yes | Voice response generation |
| Amazon Nova Sonic | Bidirectional | Yes | Real-time conversation |