Foundation Model Capabilities and Limitations
Overview
Not all foundation models are created equal. They vary in context window size, speed, reasoning ability, and what types of input they accept. Picking the right model means understanding these tradeoffs.
Amazon Bedrock gives you access to models from Anthropic, Meta, Amazon, Mistral, and others. Each has strengths and weaknesses. The exam expects you to know when to use what.
The Core Tradeoff
Every model trades off between capability, cost, speed, and context size. There's no "best" model. There's only the best model for your specific use case.
Know which models have larger context windows, faster latency, or better reasoning. Hallucination mitigation (especially RAG) comes up constantly.
Architecture Diagram

Token Limits and Context Windows
Context Windows
The context window is the maximum number of tokens a model can handle in one request. Input and output combined.
Why this matters:
- Limits how much conversation history you can include
- Determines whether a document fits in one request or needs chunking
- Affects RAG chunk sizes
- Larger windows let the model reason over more information
Current context windows: | Model | Context Window | |-------|----------------| | Claude 3.5 Sonnet/Opus | 200K tokens | | Llama 3.1/3.2/3.3 | 128K tokens | | Llama 3 (8B, 70B) | 8K tokens | | Amazon Nova Pro | 300K tokens | | Amazon Titan Text | 8K tokens | | Mistral Large | 128K tokens | | Qwen3-Coder | 256K-1M tokens |
Token Limits
Token limits cap both input and output sizes.
What you need to know:
- Input tokens: what you send (prompt, context, history)
- Output tokens: what the model generates
- Max tokens parameter: caps response length
- Combined limit: input + output can't exceed the context window
Common limits:
- Output usually capped at 4K-8K tokens per request
- Input limits vary wildly (8K to 300K)
- Embedding models often limited to 8K input
- Exceed the limit and you get a ValidationException
Cost impact:
- You pay per token, input and output priced separately
- Output tokens typically cost more than input
- Larger context = higher cost per request
Context Windows by Model
| Provider | Model | Context Window | Max Output |
|---|---|---|---|
| Anthropic | Claude 3.5 Sonnet | 200K tokens | 8K tokens |
| Anthropic | Claude 3 Haiku | 200K tokens | 4K tokens |
| Meta | Llama 3.1 70B | 128K tokens | 8K tokens |
| Meta | Llama 3 70B | 8K tokens | 2K tokens |
| Amazon | Nova Pro | 300K tokens | 5K tokens |
| Amazon | Titan Text G1 | 8K tokens | 4K tokens |
| Mistral | Mistral Large | 128K tokens | 8K tokens |
Model Strengths by Task
Different models excel at different things. Know the general patterns.
Task Strengths
Claude (Anthropic):
- Complex reasoning and analysis
- Long-form content
- Code review and explanation
- Nuanced conversation
- Strong safety alignment
Llama (Meta):
- Multilingual (8+ languages)
- Code generation
- General-purpose tasks
- Open weights (you can customize)
- Cheaper inference
Amazon Titan:
- Native AWS integration
- Embeddings for RAG
- Enterprise compliance features
- Image generation with watermarks
Mistral:
- Efficient inference
- Strong multilingual
- Mixture-of-experts architecture
- Good at code and reasoning
Model Recommendations by Use Case
| Use Case | Model | Why |
|---|---|---|
| Complex reasoning | Claude 3.5 Sonnet/Opus | Best analytical capabilities |
| Real-time chat | Claude 3 Haiku, Llama 3 8B | Low latency |
| Code generation | Claude 3.5 Sonnet, Codestral | Strong code understanding |
| Embeddings/RAG | Titan Embeddings V2 | Native integration, solid quality |
| Image generation | Titan Image, Stable Diffusion | High-quality outputs |
| Multilingual | Mistral Large, Llama 3 | Strong non-English support |
| Cost-sensitive | Llama 3 8B, Claude Haiku | Lower per-token costs |
Hallucinations
Models make things up. They do it confidently. This is the biggest risk in production GenAI.
What Hallucinations Look Like
Hallucinations = plausible-sounding but factually wrong or fabricated content.
Types:
- Factual errors: wrong facts, stats, dates
- Fabrication: made-up citations, names, events
- Conflation: mixing info from different sources
- Logical inconsistencies: contradicting itself
Why it happens:
- Models predict probable tokens, not verified facts
- Training data contains errors
- No real-time fact-checking
- Models don't know what they don't know
Mitigation Strategies
How to reduce hallucinations:
-
RAG (Retrieval-Augmented Generation)
- Ground responses in retrieved documents
- Model cites sources instead of making things up
- Primary strategy for knowledge-intensive apps
-
Bedrock Guardrails
- Contextual grounding checks
- Validates responses against provided sources
- AWS claims 99% accuracy for policy checks
-
Prompt engineering
- Tell the model to say "I don't know" when uncertain
- Request citations
- Use chain-of-thought reasoning
-
Human review
- Review high-stakes outputs
- Set confidence thresholds for escalation
- Build feedback loops
Exam Focus
RAG is the primary hallucination mitigation strategy. Know that Bedrock Guardrails with contextual grounding checks validate responses against provided sources.
Latency and Throughput
Speed matters for user experience. Know what affects it.
Latency
Latency = time from request to response.
Metrics that matter:
- Time to First Token (TTFT): how long until the first word appears
- Time to Last Token (TTLT): total generation time
- Tokens per second: generation speed
What affects latency:
- Model size (bigger = slower)
- Input length (more tokens = more processing)
- Output length (longer responses take longer)
- On-demand vs provisioned throughput
- Region (network distance)
Rough latency by model: | Model | Relative Speed | |-------|---------------| | Claude 3 Haiku | Fast (~500ms TTFT) | | Claude 3.5 Sonnet | Medium (~1s TTFT) | | Claude 3 Opus | Slow (~2s TTFT) | | Llama 3 8B | Fast | | Llama 3 70B | Medium |
Throughput
Throughput = how many requests you can handle.
Bedrock options:
-
On-Demand
- Pay per token, shared capacity
- Can get throttled under load
- Good for variable workloads
-
Provisioned Throughput
- Reserved capacity, guaranteed model units
- Lower latency, consistent performance
- Required for custom/fine-tuned models
- Higher fixed cost
Limits to know:
- Requests per minute (RPM)
- Tokens per minute (input/output)
- Varies by model and region
- You can request quota increases
Latency vs Capability
| Priority | Best Choice | Tradeoff |
|---|---|---|
| Lowest latency | Claude 3 Haiku, Llama 3 8B | Less complex reasoning |
| Best reasoning | Claude 3 Opus | Higher latency and cost |
| Balanced | Claude 3.5 Sonnet, Llama 3 70B | Good for most use cases |
| Highest throughput | Provisioned throughput | Fixed cost commitment |
Multi-Modal Capabilities
Some models handle more than text. Images, video, audio.
Multi-Modal Models
Vision (image input):
- Claude 3 models accept images
- Llama 3.2 Vision processes images
- Amazon Nova handles images and video
- Use cases: document analysis, visual Q&A, diagram understanding
Image generation:
- Amazon Titan Image Generator
- Stable Diffusion XL
- Amazon Nova Canvas
- Outputs include watermarks for provenance
Video:
- Amazon Nova Reel generates video
- Nova Pro understands video input
Multimodal embeddings:
- Amazon Titan Multimodal Embeddings
- Text and images in the same vector space
- Enables searching images with text queries
Multi-Modal Capabilities
| Model | Text In | Image In | Image Out | Video |
|---|---|---|---|---|
| Claude 3.5 | Yes | Yes | No | No |
| Llama 3.2 Vision | Yes | Yes | No | No |
| Amazon Nova Pro | Yes | Yes | No | Yes (input) |
| Titan Image Generator | Yes (prompt) | No | Yes | No |
| Stable Diffusion | Yes (prompt) | Yes (img2img) | Yes | No |
| Titan Multimodal Embeddings | Yes | Yes | No | No |
Model Selection Flow
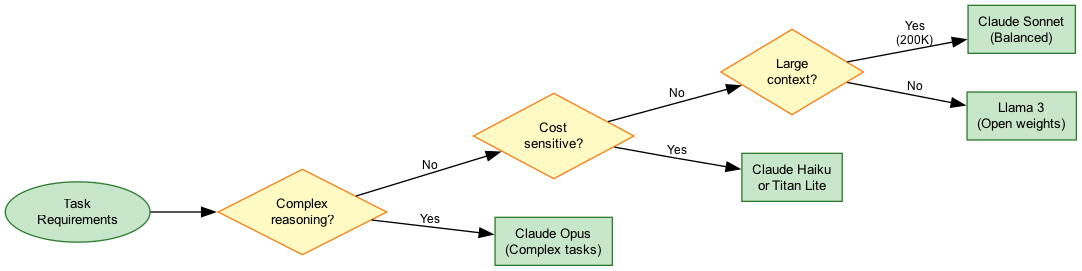
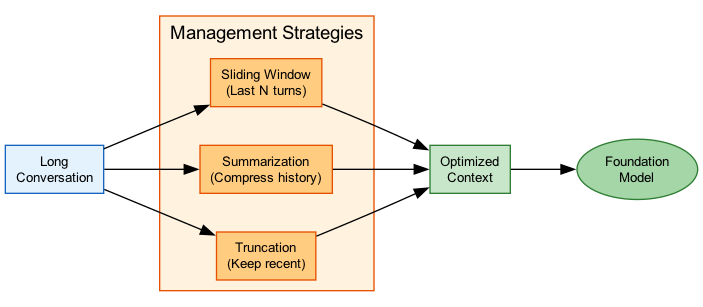
Use Cases
Long Document Summarization
Scenario: Summarize 100-page legal contracts. Need full document context.
Model choice: Claude 3.5 Sonnet (200K context) or Nova Pro (300K context)
Why:
- Large context window fits the entire document
- Strong reasoning for complex legal language
- Good at extracting key terms
Watch out for:
- Cost scales with tokens
- May still need chunking for very large docs
- Always verify with legal review
Real-Time Customer Chat
Scenario: Support chatbot that needs sub-second responses.
Model choice: Claude 3 Haiku or Llama 3 8B
Why:
- Fast time-to-first-token
- Sufficient for FAQ-style responses
- Cost-effective at scale
Watch out for:
- May need to route complex queries to a bigger model
- Use streaming for perceived speed
Multi-Modal Document Processing
Scenario: Extract info from scanned documents with images and tables.
Model choice: Claude 3.5 Sonnet with vision or Nova Pro
Why:
- Vision capabilities handle images
- Can reason about visual elements
- Good at structured extraction
Watch out for:
- Image tokens cost more
- Accuracy drops on handwritten content
- May need preprocessing for image quality
Best Practices
Model Selection
- Start with requirements. Define latency, accuracy, and cost constraints first.
- Right-size the model. Don't use Opus when Haiku will do.
- Test with real data. Benchmark on your actual use cases, not generic tests.
- Plan for context limits. Implement chunking or summarization before you hit walls.
- Monitor hallucinations. Use guardrails and measure hallucination rates.
- Consider multi-model routing. Send simple queries to small models, complex ones to big models.
Exam Scenarios
What AWS Wants You to Know
| Scenario | Answer | Why |
|---|---|---|
| Need to process 150K token document | Claude 3.5 or Nova Pro | Only models with big enough context |
| Real-time chat, <1s latency | Claude 3 Haiku or Llama 3 8B | Smallest/fastest models |
| App experiencing hallucinations | RAG + Guardrails grounding | Ground responses in facts |
| ValidationException errors | Check token limits | Probably exceeding context window |
| Need image understanding | Claude 3.5 vision or Nova Pro | Multi-modal input support |
| Cost-sensitive batch processing | Smaller model + batch inference | Lower per-token cost, 50% batch discount |
Common Mistakes
Ignoring Context Window Limits
The mistake: Sending prompts that exceed the context window without checking.
What happens: ValidationException errors or truncated context, leading to bad outputs.
Fix: Count tokens before sending. Implement chunking for long documents. Use summarization for conversation history. Pick models with appropriate context windows.
Over-Provisioning
The mistake: Using Claude 3 Opus for simple FAQ responses.
What happens: You waste money and add latency for no benefit.
Fix: Match model capability to task complexity. Use tiered routing. Benchmark multiple models. Optimize for cost-performance ratio.
Trusting Outputs Without Verification
The mistake: Deploying GenAI for critical applications without hallucination mitigation.
What happens: Models confidently state incorrect information. Users trust it. Bad things follow.
Fix: Implement RAG for knowledge-grounded responses. Use Guardrails contextual grounding. Add human review for high-stakes decisions. Monitor hallucination rates.
Test Your Knowledge
A company needs to summarize legal documents that are 180,000 tokens long. Which Amazon Bedrock model should they use?
What is the PRIMARY strategy for reducing hallucinations in GenAI applications?
An application requires sub-second response times for customer chat. Which model characteristic should be prioritized?
A model keeps returning ValidationException errors when processing long documents. What's the most likely cause?
When should you use provisioned throughput instead of on-demand?
Related Services
Quick Reference
Context Window Cheat Sheet
Claude 3.5 Sonnet/Opus: 200,000 tokens
Claude 3 Haiku: 200,000 tokens
Amazon Nova Pro: 300,000 tokens
Amazon Nova Lite: 40,000 tokens
Llama 3.1 (all sizes): 128,000 tokens
Llama 3 (8B, 70B): 8,000 tokens
Mistral Large: 128,000 tokens
Amazon Titan Text: 8,000 tokens
Qwen3-Coder: 256K-1M tokensLatency Optimization
Latency Strategies
| Strategy | Impact | Tradeoff |
|---|---|---|
| Use smaller model | High | Reduced capability |
| Reduce input tokens | Medium | Less context |
| Limit output tokens | Medium | Shorter responses |
| Provisioned throughput | High | Fixed cost |
| Regional proximity | Low-Medium | May limit model availability |
| Enable streaming | Perceived improvement | Same total time |