GenAI Architecture Fundamentals
Overview
GenAI architecture is different from traditional ML. With traditional ML, you train a model for a specific task. With GenAI, you're calling pre-trained Foundation Models (FMs) that already know how to do things. You just need to ask correctly.
Amazon Bedrock gives you access to dozens of these models as a managed service. No GPUs to provision, no training pipelines to build. You call an API, you get a response.
The Big Shift
You're not training models anymore. You're orchestrating them: managing tokens, context windows, latency, and prompts. Different skillset.
Expect questions on sync vs async processing and stateless design. AWS loves testing whether you understand that FMs don't remember anything between calls.
Architecture Diagram
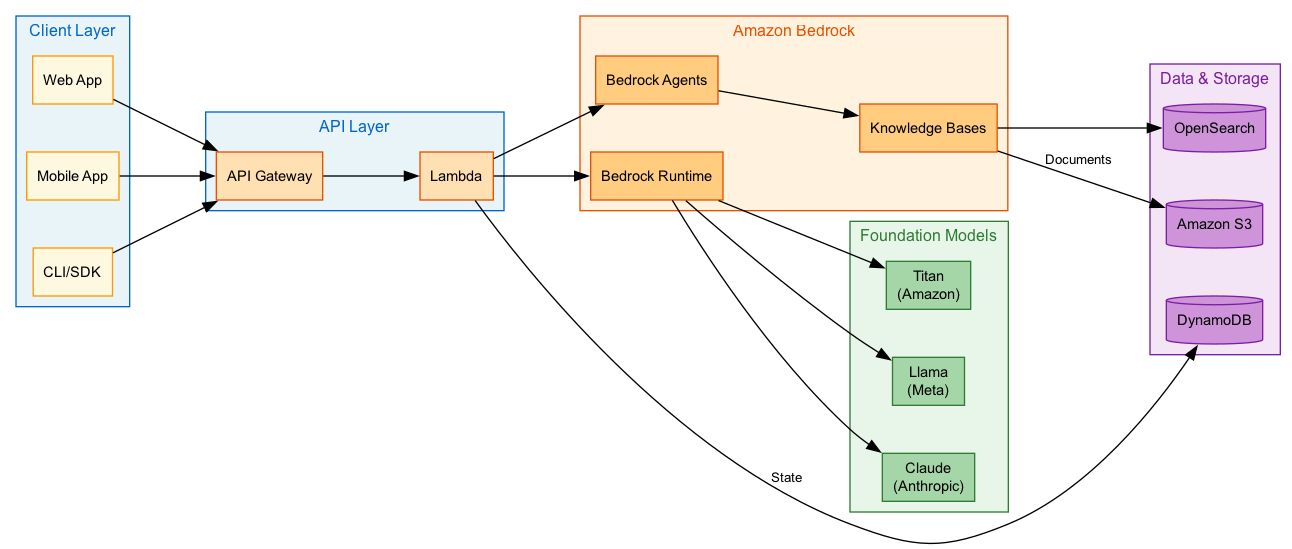
Foundation Models vs Traditional ML
Foundation Models (FMs)
Foundation Models are massive pre-trained neural networks. They already know how to write, reason, code, and generate images. You don't train them. You prompt them.
What makes them different:
- Billions of parameters, already trained
- One model handles text, code, reasoning, images (depending on the model)
- You access them through APIs
- Adaptable via prompts or fine-tuning
On Bedrock, you get:
- Claude (Anthropic): reasoning, conversation, long context
- Titan (Amazon): text, embeddings, image generation
- Llama (Meta): open-weight, good for customization
- Stable Diffusion: image generation
Traditional ML
Traditional ML means training your own model for a specific task. Fraud detection, demand forecasting, recommendations. Each needs its own model.
What that involves:
- Collecting and labeling training data
- Feature engineering (often the hard part)
- Training infrastructure (SageMaker, typically)
- Separate model for each task
Still the right choice for structured data problems. But for text, code, and conversation? FMs are usually faster to deploy.
Foundation Models vs Traditional ML
| Aspect | Foundation Models | Traditional ML |
|---|---|---|
| Training | Already done, inference only | You train it yourself |
| Data needed | Prompts and context | Large labeled datasets |
| Skills required | Prompt engineering | ML engineering, feature work |
| Flexibility | One model, many tasks | One model per task |
| Cost | Pay per token | Training + inference |
| Time to production | Hours to days | Weeks to months |
| AWS Service | Bedrock | SageMaker |
Inference vs Training
For this exam, focus on inference. Most questions are about building apps that call models, not training them.
Inference
Inference = calling a trained model to get output. This is what you'll do 99% of the time with Bedrock.
What it looks like:
- Latency matters (users are waiting)
- Stateless: each call is independent
- Scales automatically
- Pay per request/token
Bedrock handles:
- Load balancing across model instances
- Auto-scaling based on demand
- Regional endpoints for lower latency
Training (Custom Models)
Training = teaching a model new patterns. With Bedrock, this means fine-tuning or continued pre-training.
When you'd do this:
- Model needs domain-specific knowledge
- You want consistent style/format
- Base model isn't performing well enough
Bedrock options:
- Supervised Fine-Tuning (SFT): labeled examples
- Continued Pre-Training (CPT): unlabeled domain text
- Takes hours, model stored in your account
Exam Focus
Most exam questions involve inference architectures. Know the tradeoffs: on-demand vs provisioned throughput vs batch. Training questions are less common.
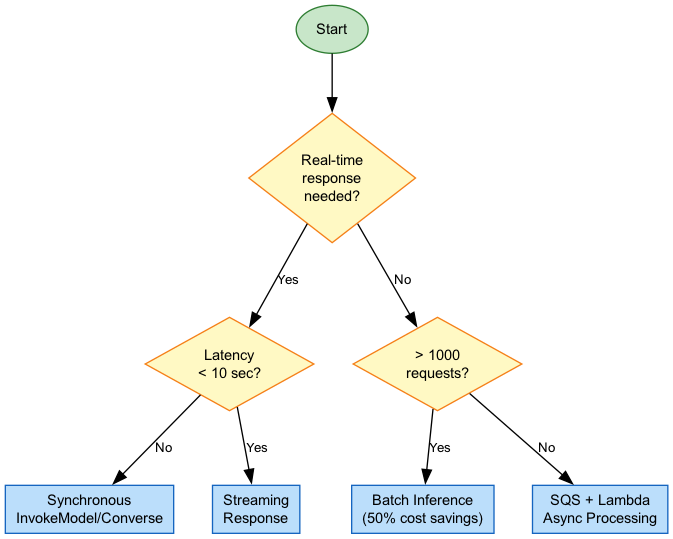
Sync vs Async Processing
The choice is simple: is someone waiting for the response?
Synchronous
User is staring at a loading spinner. They need an answer now.
When to use it:
- Chatbots
- Search interfaces
- Code completion in IDEs
- Any interactive UI
Bedrock APIs:
InvokeModel: single request, single responseInvokeModelWithResponseStream: tokens stream back as generatedConverse: multi-turn conversation helper
Constraints:
- Need sub-10-second responses (ideally faster)
- Can hit rate limits if you're not careful
- More expensive per token than batch
Asynchronous (Batch)
Nobody's waiting. You've got 50,000 documents to process overnight.
When to use it:
- Bulk content generation
- Document classification at scale
- Data extraction from archives
- Anything where "done by morning" is fine
Bedrock Batch Inference:
- Submit prompts in bulk, results land in S3
- Up to 50% cheaper than sync (finally, a discount that matters)
- No latency requirements
Typical architecture:
- S3 for input/output
- Step Functions for orchestration
- SQS if you need queuing
- SNS for completion notifications
Sync vs Async
| Aspect | Synchronous | Asynchronous |
|---|---|---|
| Latency | Real-time (seconds) | Minutes to hours |
| Cost | Standard rates | Up to 50% cheaper |
| Use case | Interactive apps | Bulk processing |
| Scaling | Bedrock handles it | Queue-based |
| Error handling | Retry immediately | DLQ + retry policies |
Stateless Design (This Is Important)
Foundation models don't remember you. Every API call starts fresh. That conversation you had 30 seconds ago? The model has no idea.
Stateless Architecture
FMs are stateless. Each request is independent. If you want conversation memory, you have to build it yourself.
What this means:
- Pass the full conversation history with every request
- Store that history somewhere (DynamoDB works well)
- Use session IDs to track who's who
- Make your operations idempotent. Retries will happen.
The upside? Scaling is trivial. Any instance can handle any request. No sticky sessions, no state synchronization headaches.
import boto3
bedrock = boto3.client('bedrock-runtime')
def chat(user_message, history):
"""
Every call includes the full conversation history.
The model doesn't remember anything on its own.
"""
messages = history + [{"role": "user", "content": user_message}]
response = bedrock.converse(
modelId="anthropic.claude-3-sonnet-20240229-v1:0",
messages=messages,
inferenceConfig={"maxTokens": 1024}
)
return response['output']['message']['content'][0]['text']
# History stored in DynamoDB, fetched per request
history = [
{"role": "user", "content": "What is AWS?"},
{"role": "assistant", "content": "AWS is Amazon Web Services..."}
]
# This call includes everything above
response = chat("Tell me about Bedrock", history)Context Management
Context = everything you send to the model. System instructions, conversation history, retrieved documents, user preferences. All of it counts against the context window.
Context Window
Context window is how much the model can "see" at once. Think of it like RAM: there's a limit.
What counts:
- System prompt
- Conversation history
- Retrieved documents (RAG)
- Your actual question
- The model's response (yes, output counts too)
Limits vary:
- Some models: 8K tokens
- Claude on Bedrock: up to 200K tokens
- Exceeding the limit = errors or truncation
Context Strategies
| Strategy | How it works | Good for |
|---|
Bedrock Memory Options
Bedrock now has Session Management APIs and AgentCore Memory. AgentCore handles both short-term (session) and long-term (user profile) memory. Worth checking if it fits your use case. Saves you from building memory infrastructure.
Request Flow

Real-World Examples
Customer Support Chatbot
The problem: Users expect instant responses. Conversations need to feel continuous.
Architecture:
- API Gateway WebSocket API (bidirectional, supports streaming)
- Lambda for request handling
- DynamoDB for conversation history
- Bedrock
ConverseAPI with streaming
Why this works:
- WebSocket lets you stream tokens to the UI as they're generated
- DynamoDB stores history; Lambda stays stateless
- Sliding window keeps context manageable
Bulk Document Processing
The problem: 100,000 legal documents need classification and summaries. Nobody's waiting.
Architecture:
- Documents in S3
- Step Functions orchestrates the workflow
- Bedrock Batch Inference does the work
- Results land back in S3
- SNS notifies when done
Why this works:
- Batch inference = 50% cost savings
- Step Functions handles retries and parallelism
- No latency pressure means you can optimize for cost
IDE Code Assistant
The problem: Developers want suggestions as they type. Speed matters.
Architecture:
- Direct HTTPS from IDE plugin to Bedrock
- Streaming API for fast first-token display
- Lambda@Edge for auth
- CloudWatch for monitoring
Why this works:
- Streaming shows results before generation completes
- Regional endpoints minimize latency
- Stateless: context passed each request
Best Practices
What Actually Matters
- Assume statelessness. Store history externally, pass it every time.
- Pick the right mode. Sync for interactive, batch for bulk.
- Watch your context window. Implement sliding window or summarization before you hit limits.
- Handle throttling. Bedrock will throttle you eventually. Exponential backoff, maybe a fallback model.
- Track tokens. Input + output tokens = your bill. Monitor this.
- Stream for UX. Users perceive streaming as faster, even when it isn't.
Exam Scenarios
What AWS Wants You to Know
| Scenario | Answer | Why |
|---|
Common Mistakes
Assuming the Model Remembers
The mistake: Expecting the model to remember your last message.
Reality: It doesn't. Every call is independent.
Fix: Store history in DynamoDB (or similar), include it in every request. Or use Bedrock's memory APIs if they fit your use case.
Using Sync for Bulk Work
The mistake: Processing 10,000 documents with individual InvokeModel calls.
Reality: You'll pay more, hit rate limits, and probably timeout somewhere.
Fix: Batch inference. It exists for this exact reason.
Ignoring Context Limits
The mistake: Appending to conversation history forever until something breaks.
Reality: You'll get 400 errors or truncated responses. The error message won't always tell you why.
Fix: Track token counts. Implement sliding window or summarization before you hit the wall.
Test Your Knowledge
A company wants to build a chatbot that maintains conversation context across multiple interactions. What is the BEST approach for managing conversation state with Amazon Bedrock?
An organization needs to process 100,000 documents for classification. Which Amazon Bedrock inference pattern should they use?
What is the PRIMARY difference between foundation models and traditional ML models?
A GenAI application is returning errors when conversations exceed 20 messages. What's the MOST LIKELY cause?
When should you use synchronous inference over batch inference?