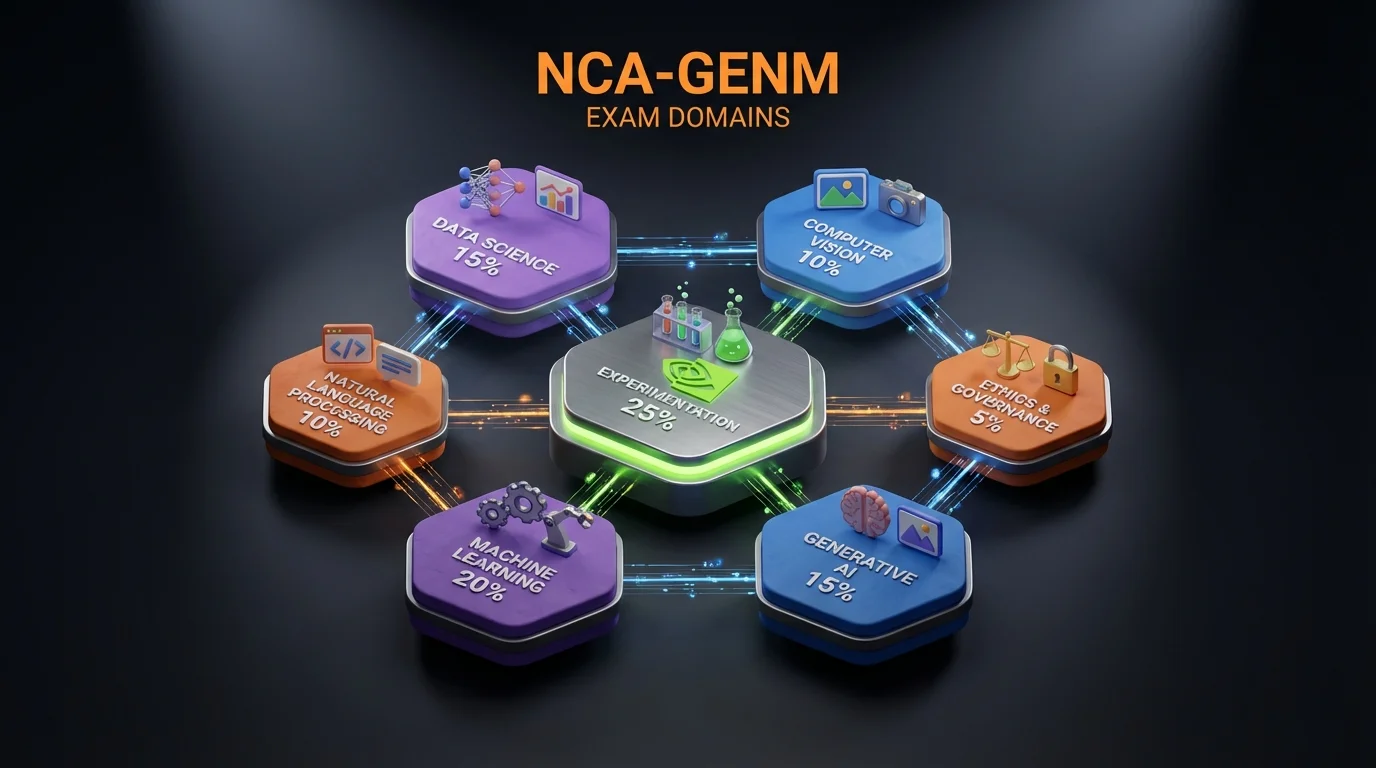
TL;DR: The NVIDIA NCA-GENM exam covers 7 domains: Experimentation (25%), Core ML and AI Knowledge (20%), Multimodal Data (15%), Software Development (15%), Data Analysis and Visualization (10%), Performance Optimization (10%), and Trustworthy AI (5%). Focus on multimodal architectures, diffusion models, and evaluation metrics — these drive the majority of questions.
The NVIDIA Certified Associate - Generative AI Multimodal (NCA-GENM) validates your foundational understanding of multimodal AI systems — models that work across text, images, audio, and video simultaneously. This entry-level certification is ideal for professionals expanding beyond text-only LLMs into the broader generative AI landscape.
Exam Quick Facts
NCA-GENM vs NCA-GENL
NCA-GENM (Multimodal Associate): Tests multimodal AI — vision transformers, diffusion models, CLIP, cross-modal systems. 7 domains with Experimentation as the largest.
NCA-GENL (LLM Associate): Tests text-only LLMs — transformer architecture, prompt engineering, RAG, fine-tuning. 5 domains with Core ML as the largest.
If your work involves images, video, or audio alongside text, NCA-GENM is the right choice. For text-only LLM work, choose NCA-GENL.
NCA-GENM Domain Weight Overview
| Domain | Weight | Est. Questions | Focus Area |
|---|---|---|---|
| 1. Experimentation | 25% | ~13-15 | Prompting, evaluation, experiment design |
| 2. Core ML and AI Knowledge | 20% | ~10-12 | ViT, CLIP, diffusion models, architectures |
| 3. Multimodal Data | 15% | ~8-9 | Data preprocessing, augmentation, pipelines |
| 4. Software Development | 15% | ~8-9 | Tools, libraries, deployment, APIs |
| 5. Data Analysis and Visualization | 10% | ~5-6 | Visualization, monitoring, interpretation |
| 6. Performance Optimization | 10% | ~5-6 | Quantization, inference speed, serving |
| 7. Trustworthy AI | 5% | ~3 | Bias, safety, watermarking, privacy |
Based on 50-60 questions. Distribution may vary between exam versions.
Recommended Study Time Allocation
Allocate study time based on weight AND difficulty:
- Experimentation (25%): 25% of study time — Largest domain, highly testable
- Core ML and AI (20%): 25% of study time — Foundational, harder concepts need extra attention
- Multimodal Data (15%): 15% of study time — Data-specific topics
- Software Development (15%): 15% of study time — Tools and libraries
- Data Analysis (10%): 8% of study time — More intuitive
- Performance Optimization (10%): 8% of study time — Practical optimization
- Trustworthy AI (5%): 4% of study time — Smallest domain, know the basics
Preparing for NCA-GENM? Practice with 455+ exam questions
Domain 1: Experimentation (25%)
Run experiments against real diffusion models
Prompt iteration, guidance-scale sweeps, and CLIP/FID evaluation become intuitive once you've done them on a live Stable Diffusion + LoRA pipeline. MLflow tracks runs for you automatically.
- Open labFine-Tune Stable Diffusion with LoRA: Custom Text-to-Imageintermediate 45 minGPU sandbox
- Open labMLflow Experiment Tracking: From Single Run to Team Workflowintermediate 35 minGPU sandbox
- Open labVisual Q&A with NVIDIA VLMsintermediate 30 minHosted
- Open labReproducible Training: The Flags, The Cost, The Artifactsintermediate 40 minGPU sandbox
This is the largest domain. It tests your ability to design experiments with multimodal models, engineer prompts for image generation, evaluate outputs, and tune hyperparameters.
Core Topics
- •Experiment design methodology for multimodal systems
- •Text-to-image prompt engineering: positive and negative prompts
- •Prompt weighting and compositional prompting
- •Few-shot and zero-shot prompting for vision-language models
- •Image generation evaluation: FID (Frechet Inception Distance)
- •Image generation evaluation: Inception Score (IS)
- •Text-image alignment evaluation: CLIP Score
- •Captioning evaluation: BLEU, CIDEr, METEOR
- •Diffusion model hyperparameters: guidance scale, inference steps
- •Scheduler selection: DDPM, DDIM, Euler, DPM-Solver
- •Fine-tuning multimodal models: LoRA, DreamBooth, Textual Inversion
- •A/B testing generated outputs
- •Ablation studies for architecture decisions
- •Experiment tracking and reproducibility (seeds, configs)
Skills Tested
Example Question Topics
- A user wants sharper images from a diffusion model. Which parameter should they increase first?
- You need to compare two image generation models on realism. Which metric is most appropriate?
- When would you use DreamBooth instead of LoRA for fine-tuning a diffusion model?
- How does increasing classifier-free guidance scale beyond 15 typically affect output?
Key Evaluation Metrics
Multimodal Evaluation Metrics
| Metric | Measures | Scale | Use Case |
|---|---|---|---|
| FID (Frechet Inception Distance) | Quality + diversity of image distribution | Lower is better | Comparing generation models overall |
| Inception Score (IS) | Quality + diversity via classifier confidence | Higher is better | Quick quality check for generated images |
| CLIP Score | Text-image alignment | Higher is better | Does the image match the prompt? |
| BLEU | N-gram overlap with reference text | 0-1 (higher = better) | Image captioning quality |
| CIDEr | Consensus-based caption evaluation | Higher is better | Captioning with multiple references |
| METEOR | Word-level alignment with synonyms | 0-1 (higher = better) | Captioning with paraphrases |
Diffusion Model Hyperparameters
| Parameter | Effect of Increasing | Typical Range | Exam Tip |
|---|---|---|---|
| Guidance Scale | Stronger prompt adherence, less diversity | 5-15 | Too high (>20) causes artifacts and saturation |
| Inference Steps | Higher quality, slower generation | 20-50 | Diminishing returns after 30-50 steps |
| Scheduler | Controls denoising trajectory | DDIM, Euler, DPM | DDIM faster, DPM-Solver++ most efficient |
| Seed | Reproducibility of outputs | Any integer | Same seed + same params = same output |
Common Exam Trap
Question pattern: "What happens when you set guidance scale to 1.0?"
Answer: The model generates images without text conditioning — essentially random image generation. Guidance scale of 1.0 means no classifier-free guidance is applied. This is a frequently tested edge case. Typical production values are 7-12.
Fine-Tuning Approaches for Diffusion Models
Diffusion Model Fine-Tuning Methods
| Method | What It Does | Data Needed | Best For |
|---|---|---|---|
| LoRA | Adds low-rank adapter weights | 50-500 images of a style | Style transfer, consistent aesthetics |
| DreamBooth | Teaches model a new concept/subject | 3-10 images of a subject | Personalization (your face, your product) |
| Textual Inversion | Learns a new token embedding | 5-15 images | Lightweight concept learning |
| Full Fine-Tuning | Updates all model weights | 1000+ images | Large-scale domain adaptation |
Domain 2: Core ML and AI Knowledge (20%)
Build a transformer and see cross-attention live
ViT, diffusion, and cross-attention are easier to reason about once you've trained a transformer and used a VLM. Two labs, foundations of the whole domain.
This domain tests the architectural foundations of multimodal AI. You must understand how Vision Transformers process images, how CLIP aligns modalities, and how diffusion models generate images.
Vision Transformer (ViT) Architecture
How ViT processes images:
- Patch Extraction: Split image into fixed-size patches (e.g., 224x224 image into 196 patches of 16x16)
- Linear Projection: Each patch is flattened and projected to embedding dimension
- Position Embedding: Learnable position embeddings added to preserve spatial information
- CLS Token: Special classification token prepended to the sequence
- Transformer Encoder: Standard transformer self-attention across all patch tokens
- Output: CLS token output used for classification; all tokens for dense prediction
Key insight: ViT treats images like text — patches are "visual tokens." This allows vision models to use the same transformer architecture as language models.
CLIP (Contrastive Language-Image Pre-training)
Architecture: Two separate encoders — one for text, one for images — trained to produce similar embeddings for matching pairs and different embeddings for non-matching pairs.
Training objective: Given a batch of N text-image pairs, CLIP maximizes the cosine similarity of the N correct pairs while minimizing similarity for all N^2 - N incorrect pairs. This is contrastive learning.
Zero-shot classification: To classify an image, create text prompts for each class ("a photo of a dog", "a photo of a cat"), encode them all, and select the class whose text embedding is most similar to the image embedding. No fine-tuning required.
CLIP Is Everywhere in NCA-GENM
CLIP appears across multiple domains: as an architecture (Core ML), as an evaluation metric (CLIP Score in Experimentation), and as a tool for understanding embeddings (Data Analysis). Master how CLIP works — you will see it tested from multiple angles.
Diffusion Models
Forward process (training):
- Gradually add Gaussian noise to a real image over T timesteps
- At step T, the image is pure random noise
- This is a fixed process (no learning happens here)
Reverse process (the model learns this):
- A neural network (typically U-Net) learns to predict and remove noise at each step
- Given a noisy image and timestep t, predict the noise that was added
- At inference: start from pure noise, iteratively denoise to produce an image
Latent diffusion (Stable Diffusion):
- A VAE encoder compresses the image to a smaller latent representation
- Diffusion happens in this latent space (much cheaper computationally)
- A VAE decoder converts the final denoised latent back to pixel space
- Text conditioning is applied via cross-attention in the U-Net
Core ML Gotchas
Common exam traps:
- ViT patches are fixed-size (typically 16x16 or 32x32), not learned regions
- CLIP does NOT generate images — it aligns text and image representations
- In latent diffusion, the U-Net denoises in latent space, not pixel space
- Cross-attention in Stable Diffusion: text provides K and V, image latent provides Q
- VAEs use KL divergence to regularize the latent space, not just reconstruction loss
- ViT position embeddings are typically learned, not fixed sinusoidal (unlike original transformer)
Domain 3: Multimodal Data (15%)
Feed real multimodal data to a multimodal RAG
Text-image pairs, patch embeddings, and multimodal retrieval land faster with a working multimodal RAG + VLM QA pipeline.
This domain tests your understanding of data preparation, augmentation, and pipelines for multimodal training and inference.
Image Preprocessing Pipeline
| Step | Purpose | Typical Values |
|---|---|---|
| Resize | Match model input size | 224x224 (ViT), 512x512 (Stable Diffusion) |
| Center Crop | Remove borders, focus on subject | Square crop for most models |
| Normalize | Scale pixel values | ImageNet mean/std or [0, 1] range |
| To Tensor | Convert to model-compatible format | Channel-first (C, H, W) |
Augmentation Rules for Multimodal Data
Critical Rule
When augmenting text-image pairs, the augmentation must preserve the relationship between modalities.
Safe augmentations (preserve text-image alignment):
- Horizontal flip (unless text describes left/right orientation)
- Random crop (if the described object remains visible)
- Color jitter (mild — unless text describes specific colors)
- Rotation (small angles, unless text describes orientation)
Unsafe augmentations (can break alignment):
- Aggressive crop that removes the described subject
- Color changes when text describes specific colors ("a red car" + color jitter that makes it blue)
- Vertical flip of scenes with gravity ("a cat sitting on a table" flipped upside down)
Audio and Video Data
Audio representations for AI models:
- Raw waveform: Direct amplitude over time, used by WaveNet-style models
- Spectrogram: Time-frequency representation, can be processed like an image
- Mel spectrogram: Spectrogram with perceptually-motivated frequency scale
- MFCC: Compact features derived from mel spectrogram, used in speech processing
Video data handling:
- Uniform sampling: Extract frames at regular intervals (every Nth frame)
- Keyframe extraction: Select frames with significant visual changes
- Temporal stride: Skip frames to reduce temporal redundancy
- Clip sampling: Extract short clips (e.g., 16 frames) for video understanding models
Domain 4: Software Development (15%)
Ship multimodal pipelines with Hugging Face + NIM
Hugging Face Diffusers, VLM inference, and multimodal API design become concrete after you've wired up all three. Our labs ship with working reference implementations.
This domain tests your knowledge of tools, libraries, and deployment strategies for multimodal AI applications.
NVIDIA Tools Quick Reference
NVIDIA Tools for Multimodal AI
| Tool | What It Does | When to Use |
|---|---|---|
| NVIDIA NeMo | Framework for building and training AI models | Developing custom multimodal models from scratch |
| NVIDIA Picasso | Cloud-native visual content generation service | Enterprise image, video, and 3D generation |
| NVIDIA NIM | Pre-optimized microservices for model deployment | Quick production deployment of AI models |
| NVIDIA Triton | Inference server for model serving at scale | High-throughput, multi-model serving in production |
| NVIDIA TensorRT | Inference optimization engine | Maximizing inference speed on NVIDIA GPUs |
| Hugging Face Diffusers | Open-source diffusion model library | Prototyping, experimentation, fine-tuning |
Hugging Face Diffusers Basics
Loading a pipeline:
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1",
torch_dtype=torch.float16
)
pipe = pipe.to("cuda")
image = pipe(
prompt="a photo of an astronaut riding a horse",
negative_prompt="blurry, low quality",
num_inference_steps=30,
guidance_scale=7.5
).images[0]
Key API patterns to know:
from_pretrained()— Load models from Hugging Face Hubpipe.to("cuda")— Move to GPU for inferenceguidance_scale— Controls prompt adherencenum_inference_steps— Quality vs speed trade-offnegative_prompt— What NOT to generate- Changing schedulers:
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
Exam Tip: Tools Domain
The exam does not ask you to write code from scratch. It tests whether you understand WHEN to use each tool and HOW the key APIs work at a conceptual level. Know the purpose of each NVIDIA tool, understand the Diffusers pipeline API, and be able to identify the correct tool for a given scenario.
Master These Concepts with Practice
Our NCA-GENM practice bundle includes:
- 7 full practice exams (455+ questions)
- Detailed explanations for every answer
- Domain-by-domain performance tracking
30-day money-back guarantee
Domain 5: Data Analysis and Visualization (10%)
This domain tests your ability to interpret and visualize multimodal model behavior.
Visualization Techniques
| Technique | What It Shows | Use Case |
|---|---|---|
| Attention Maps | Which image regions the model focuses on | Debugging and explaining predictions |
| Grad-CAM | Gradient-weighted class activation maps | Understanding classification decisions |
| t-SNE / UMAP | Low-dimensional projection of embeddings | Checking if CLIP embeddings are well-organized |
| Training Curves | Loss and metrics over training steps | Detecting overfitting, underfitting, divergence |
| FID over Epochs | Generation quality during training | Deciding when to stop training |
Interpreting Training Curves
Healthy training:
- Training loss decreases steadily
- Validation loss tracks training loss closely
- FID decreases (quality improves) and then plateaus
Signs of trouble:
- Overfitting: Training loss drops, validation loss rises or plateaus
- Underfitting: Both losses remain high, model not learning
- Divergence: Loss spikes or becomes NaN — learning rate too high
- Mode collapse: FID is low but IS is also low — model generates limited variety
Domain 6: Performance Optimization (10%)
Quantize, profile, and batch your way to speed
Quantization and diffusion-step tradeoffs are pure numbers — easier to answer when you've benchmarked them. Precision-sweep + quantization + Nsight cover this domain.
- Open labQuantize & Optimize LLMs with bitsandbytesintermediate 40 minGPU sandbox
- Open labBatch Size & Precision Sweep: Finding Your Sweet Spotintermediate 40 minGPU sandbox
- Open labNsight Systems Profiling: Finding the Bottleneck That Costs You 40% of Your GPUintermediate 35 minGPU sandbox
- Open labProfile PyTorch Training with the Built-in Profilerintermediate 35 minGPU sandbox
- Open labCUDA Programming Fundamentalsadvanced 45 minGPU sandbox
This domain tests practical knowledge of making multimodal models faster and more efficient.
Quantization Quick Reference
| Precision | Bytes/Param | Memory (1B model) | Speed vs FP32 | Quality Impact |
|---|---|---|---|---|
| FP32 | 4 | 4 GB | Baseline | Baseline |
| FP16 | 2 | 2 GB | ~2x faster | Negligible |
| INT8 | 1 | 1 GB | ~3-4x faster | Minimal with calibration |
| INT4 | 0.5 | 0.5 GB | ~4-6x faster | Noticeable, needs careful calibration |
Diffusion Model Speed Optimization
| Technique | Speed Improvement | Quality Impact | Complexity |
|---|---|---|---|
| Fewer steps (50 to 20) | ~2.5x faster | Mild quality loss | Easy |
| Faster scheduler (DDIM) | ~2-5x fewer steps needed | Minimal with good scheduler | Easy |
| FP16 inference | ~2x faster | Negligible | Easy |
| TensorRT compilation | ~2-3x faster | None (optimization only) | Medium |
| Step distillation | ~4-8x fewer steps | Requires training distilled model | Hard |
| Model pruning | Variable | Depends on pruning ratio | Medium |
Optimization Decision Tree
Need faster inference? Follow this order:
- Use FP16 (free speed, no quality loss)
- Reduce inference steps to 25-30 with a good scheduler
- Apply TensorRT optimization
- Use dynamic batching in serving
- Consider model distillation for extreme speed requirements
Domain 7: Trustworthy AI (5%)
The smallest domain — but do not skip it. Every question counts, and these are straightforward if you know the basics.
Key Trustworthy AI Concepts
| Concept | What to Know | Exam Relevance |
|---|---|---|
| Visual Bias | Models may generate stereotypical images for certain prompts | High — know how to detect and measure |
| NSFW Filtering | Safety classifiers check generated content before delivery | Medium — know it exists and why |
| Watermarking | Invisible markers embedded in generated images | High — know purpose and methods |
| Deepfakes | AI-generated realistic face images/videos | Medium — know risks and detection |
| Data Provenance | Tracking what training data was used | Low — general awareness |
| EU AI Act | Risk-based regulation of AI systems | Low — general awareness |
Domain-by-Domain Study Strategy Summary
Study Strategy Summary
| Domain | Weight | Study Hours* | Priority | Key Focus |
|---|---|---|---|---|
| Experimentation | 25% | 12-15h | Highest | Prompting, metrics, hyperparameters |
| Core ML & AI | 20% | 12-15h | Highest | ViT, CLIP, diffusion models |
| Multimodal Data | 15% | 7-8h | High | Preprocessing, augmentation, alignment |
| Software Dev | 15% | 7-8h | High | Hugging Face, NVIDIA tools |
| Data Analysis | 10% | 4-5h | Medium | Visualization, monitoring |
| Optimization | 10% | 4-5h | Medium | Quantization, speed |
| Trustworthy AI | 5% | 2-3h | Lower | Bias, safety, watermarking |
Based on 50-60 total study hours for someone with basic ML/programming background.
Next Steps
- Start with the complete guide: Read the NCA-GENM Complete Guide for the full certification overview
- Follow a structured plan: Use our 4-week study plan with daily tasks
- Get exam-day ready: Read the first-attempt pass guide for strategies and common mistakes
- Quick review: Bookmark the NCA-GENM cheat sheet for last-minute revision
- Practice: Take a practice test to measure your readiness
Ready to Pass the NCA-GENM Exam?
Join thousands who passed with Preporato practice tests